The SDD Wave
Last month, I received a 21GB enterprise Java monorepo — Eclipse Tycho, OSGi bundles, Elasticsearch 5.x, Hibernate Search, a custom federation layer — and three days to understand it. No documentation. No architect available. Welcome to the real world of software development.
That project forced me to formalize something I'd been building for months. It also showed me exactly where the current conversation about AI development falls short.
In early 2026, a term started appearing everywhere: Spec-Driven Development. The idea is simple and correct — write detailed specifications, then let AI agents implement the code. Tools like GitHub Spec Kit, AWS Kiro, and Tessl formalized what many of us were already doing: using specs as the primary artifact and AI as the executor.
This is good. This is progress. Specs as first-class artifacts is the right direction.
But after months of running this approach in production — across greenfield apps, enterprise brownfield codebases, and operational data pipelines — I've found that SDD, as currently defined, solves about 40% of the actual problem.
I call the other 60%: AID — AI-Integrated Development.
What AID Means
SDD says: the spec drives development. The human writes the spec, the AI executes it.
AID says: human and AI co-execute the entire lifecycle. Six phases — discover, interview, specify, plan, detail, execute — plus the optional deploy and monitor skills, covering the full journey from discovery to production monitoring. The AI is the Iron Man suit — it amplifies the human. The human is the pilot — setting direction, making decisions, approving advancement between stages. The human never leaves the cockpit.
This is not "AI executes, human validates." It is "human + AI work together, human drives."
The distinction matters because it changes what the methodology covers:
| SDD | AID | |
|---|---|---|
| Starting point | You have a spec | You have a problem |
| Scope | Spec → Code | Problem → Production → Monitor → Loop |
| AI role | Executor | Co-pilot across all phases |
| Human role | Spec writer, reviewer | Pilot — drives every phase, approves transitions |
| Brownfield | Not addressed | Stage 1 (Discovery + Knowledge Base) |
| Feedback | Linear (spec → code → done) | 10 formal loops including production → development |
| Post-delivery | Not addressed | Monitor → Execute (bugs) / Discover (CRs) |
AID contains SDD. SDD is the spec→code layer. AID is the complete lifecycle.
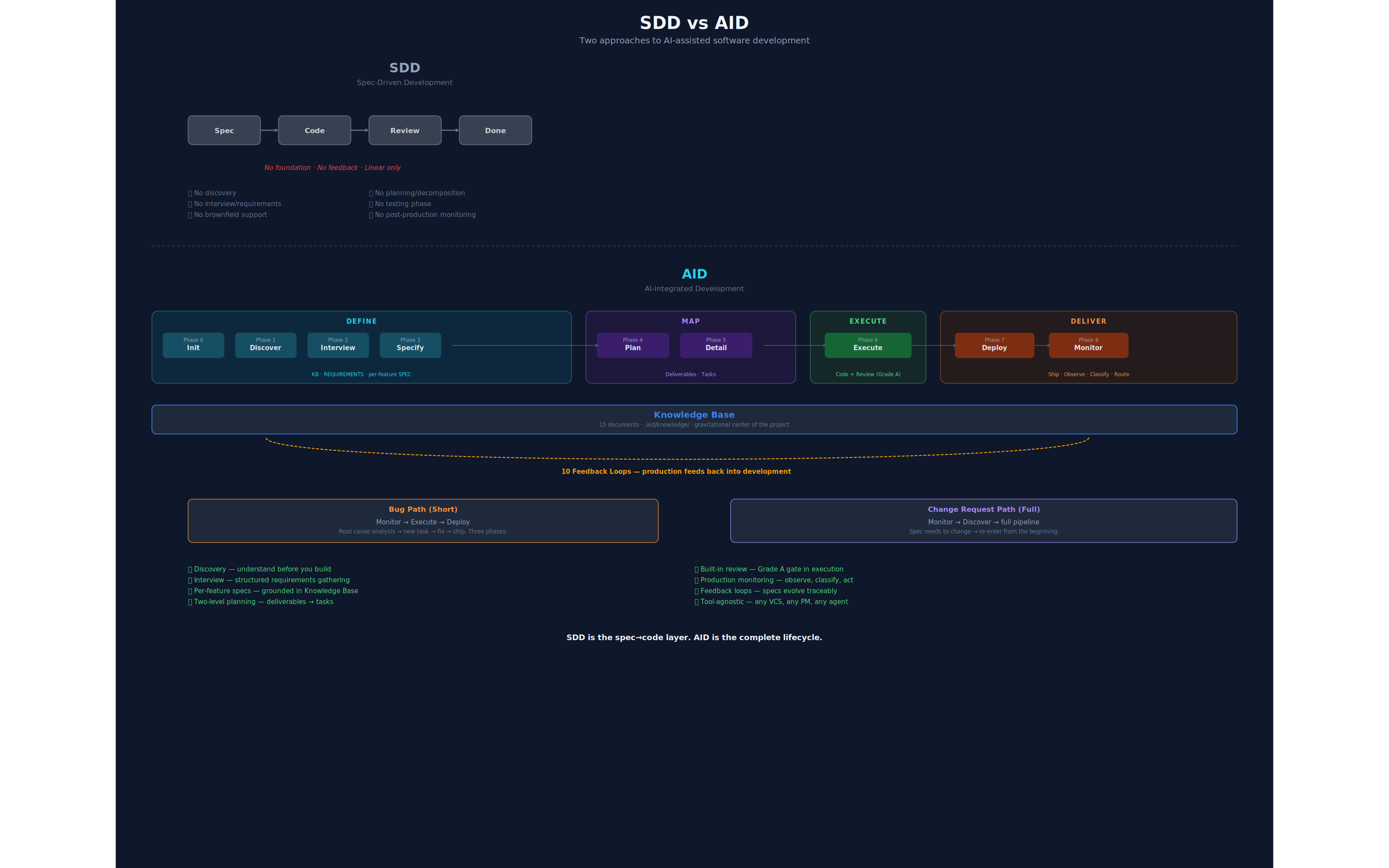
Both are linear. SDD floats without foundation. AID is built on the Knowledge Base, with feedback loops at every stage.
Problem 1: Brownfield Doesn't Exist in SDD
SDD's biggest blind spot is existing code. Every SDD tool assumes you're either starting from scratch or already have clean specifications. The community knows this:
"Support for brownfield projects (existing codebases without specifications)" — InfoQ, listing SDD's short-term gaps
"Greenfield easy. If brownfield, clean up your garbage code first before writing bad specs for bad code." — r/ExperiencedDevs
Enterprise is 90% brownfield. A methodology that only works on greenfield projects is a conference talk, not a production strategy.
AID's answer: the Knowledge Base.
Before you can write a spec for an existing system, you need to understand that system. Not a README that was last updated in 2019 — a living, verified understanding. AID produces a Knowledge Base — not a single document, but a structured collection:
.aid/knowledge/
├── README.md # Index with completeness tracking
├── INDEX.md # Lightweight context map for agent self-service
├── architecture.md # Patterns, layers, boundaries, data flow
├── module-map.md # Every module: purpose, deps, size, coverage
├── technology-stack.md # Languages, frameworks, versions, build/lint/test commands
├── coding-standards.md # Conventions observed in the actual code
├── data-model.md # Schema, entities, relationships
├── api-contracts.md # APIs consumed and exposed
├── integration-map.md # Queues, caches, third-party services
├── domain-glossary.md # Business terms in the team's language
├── test-landscape.md # Frameworks, coverage, CI/CD, test commands
├── security-model.md # Auth, secrets, compliance
├── tech-debt.md # Known debt with risk ratings
├── infrastructure.md # Hosting, CI/CD, source control, deployment
└── ui-architecture.md # Component patterns, state, design system, a11yThat 21GB monorepo I mentioned? The AI agent produced a 14-document Knowledge Base in a single session. That KB became the foundation for every specification that followed.
The Knowledge Base isn't a one-time artifact. It's the gravitational center of the project — every phase reads from it, and any phase can trigger updates to it. The KB outlives the project. It's institutional memory.
SDD starts at the spec. AID starts at understanding.
Problem 2: Specs Are Hypotheses, Not Sacred Texts
SDD treats the specification as the source of truth. Write the spec, then implement it. If the implementation diverges, the implementation is wrong.
This works when specs are correct. In practice, specs are your best understanding at the time — and implementation is where you discover they were wrong.
Real examples:
- Planning a feature revealed that the module map showed 3 consumers of a service, but
grepfound 11. The spec assumed a simple refactor. Reality disagreed. - Implementing a task discovered that a service documented as async was actually synchronous. The task spec's approach was invalid.
- Testing in staging revealed that a feature worked perfectly in isolation but broke under concurrent load — something no static review could catch.
SDD's answer: write better specs. AID's answer: build formal feedback loops.
Eleven Feedback Loops
Every downstream phase can trigger an upstream revision — not by restarting from scratch, but through a structured protocol:
Development loops (1–8):
- Interview → Discovery — Client's answer reveals the KB is wrong or incomplete
- Spec → Discovery — Writing the spec exposes that we don't understand a subsystem
- Plan → Discovery — Planning reveals hidden complexity
- Plan → Spec — Spec is ambiguous but KB is complete (requirements problem, not knowledge problem)
- Detail → Plan — Plan is too vague to decompose into tasks
- Execute → Any upstream — Reality check. Documented as IMPEDIMENT.md with options
- Execute Review → Any upstream — Quality gate catches issues that trace to spec or architecture
- Test → Execute — Staging tests fail, route back for fix
Post-production loops (9–10):
- Monitor → Interview — Production bug routed through the lite bug-fix triage (short path)
- Monitor → Interview — Change request routed as new/changed requirements (full path)
Cross-cutting loop (11):
- Any phase → Discover — Targeted re-discovery when the Knowledge Base is found lacking mid-pipeline
Every loop produces a formal artifact (GAP.md, IMPEDIMENT.md, or MONITOR-STATE.md) with a revision trail. The spec evolves, but traceably. You can always answer "why did this change?" with evidence.
The complete AID pipeline — six phases plus the optional Deploy & Monitor skills, with the Knowledge Base at center and eleven feedback loops.
SDD is linear and floating: spec → code → done.
AID is linear but grounded: discover → specify → execute → deploy → monitor → loop — built on the Knowledge Base, with feedback loops that keep the system learning.
Problem 3: Requirements Are a Skill, Not a Prerequisite
SDD assumes you already have requirements. Kiro starts with "describe what you want." Spec Kit starts with a written description.
But clients don't hand you specifications. They hand you a problem, a vague idea, and a budget.
AID includes an adaptive interview process. Not a questionnaire — a conversation where each answer shapes the next question. The interview maintains a knowledge model tracking what's known, unknown, or assumed:
business.type known answer #1
features.priority_list unknown → next question
technical.platform known from KB (brownfield)
constraints.compliance unknown → ask laterBrownfield interviews are shorter (technical fields pre-filled from discovery). Greenfield interviews are longer. Returning clients reuse prior requirements as starting state.
The output is a structured REQUIREMENTS.md with features decomposed into individual specs — not a meeting transcript.
Problem 4: Code Generation Is Not Delivery
SDD ends at code generation. Spec Kit's /implement produces code. Kiro produces tasks. Tessl compiles specs.
Code generation is maybe 30% of shipping software.
AID covers the full cycle:
- Two-level planning — Plan (strategy: sequenced deliverables) → Detail (tactics: small, sequential, testable tasks)
- Incremental deliveries — not one massive spec-to-code pass, but deliberate stages each with execute → deploy
- Multi-agent orchestration — parallel agents for independent features, specialist agents for different concerns
- Built-in review and testing — code review is built into execution (Grade A gate), staging validation via dedicated test tasks
- Domain-specific quality gates — "does the revenue number match source data within 1%?" not just "does it compile"
- Human-in-the-middle — the human co-pilots every phase and approves every transition
In one production pipeline, 12 specialist AI agents across 3 brands produce reports validated against source data with 1% tolerance. Each agent can fail and retry up to 3 times. The quality gate catches hallucinated numbers. The orchestrator has one rule: NEVER CALCULATE — copy exactly from source.
This isn't code generation. This is operational engineering. SDD has no vocabulary for it.
Problem 5: Shipping Is Not the End
SDD's lifecycle ends at code generation. Most methodologies end at delivery. The code ships, the PR merges, and... what? You hope it works?
In production, things break. Users discover edge cases. Business rules change. Third-party APIs update. The question isn't if something will need attention after delivery — it's how fast you catch it and how correctly you route it.
AID adds a Monitor phase that closes the loop — observe, classify, act in a single cycle:
Monitor observes production — not just collecting metrics, but interpreting and routing them. An AI agent reads error logs, test results, performance metrics, and issue trackers. It tells you "error rate increased 340% in the payment module after deploy #47, affecting ~2,000 users, correlating with the async refactor in the last delivery." Then it classifies each finding and routes it:
- Bugs take a short path: Monitor performs root cause analysis, creates a task, routes to Execute → Deploy. Three phases. No re-specification. The spec was right; the code was wrong.
- Change Requests take the full path: Back to Discover. New requirements, new spec, new plan. The spec needs to evolve, so the full pipeline runs.
SDD ends at code. AID ends at... it doesn't end. The pipeline is a loop.
The Human Never Leaves the Cockpit
Every phase in AID is co-executed by human and AI. The AI is the Iron Man suit — it amplifies what the human can do. The human is the pilot — setting direction, making judgment calls, approving advancement.
The Iron Man model in motion — the human issues the command; the AID pipeline executes phase by phase and halts for a human OK at every step. The pilot never leaves the cockpit.
Between stages and phases, the human reviews the output and gives the OK to proceed. The pipeline never auto-advances. This is the checkpoint that keeps the methodology safe without slowing it to human speed.
This framing matters:
- Not "AI executes, human reviews." That's delegation with a rubber stamp.
- Not "human thinks, AI types." That's a fancy text editor.
- "Human + AI work together. Human drives." That's a power multiplier.
The human brings judgment, domain expertise, and accountability. The AI brings speed, thoroughness, and consistency. Neither is sufficient alone. Together, they're dangerous.
Tooling Integration
AID is a methodology, not a tool. Each phase can be implemented as a reusable agent skill or prompt in any agentic coding tool — Claude Code, Codex, Cursor, Windsurf, Aider, or whatever comes next. The methodology is the value, not the tooling.
AID orchestrates existing tools rather than replacing them:
- GitHub Issues / Jira / Linear → Monitor phase. Production findings classified and routed. PM sync is tool-agnostic.
- GitHub Actions / CI Workflows → Execute and Deploy phases. Automated test suites, staging deployment, production release.
- Pull Requests / Merge Reviews → Execute phase (built-in review). Structured descriptions with task and delivery context.
- SpecIT / Kiro → Specify phase. AID doesn't care how you write specs — it cares that specs are grounded in the KB.
- Any AI coding agent → Execute phase. Agent-per-task execution with full KB context.
Setup is a persistent global aid CLI. You bootstrap it once per machine (curl … install.sh | bash, npm i -g aid-installer, or pipx install aid-installer), run aid add <tool> (e.g. aid add claude-code) in your repo, then run /aid-config to scaffold the Knowledge Base — 14 standard documents under .aid/knowledge/ plus three meta-docs (INDEX.md, README.md, STATE.md), configurable per project via discovery.doc_set. Agents always start with a consistent project layout, greenfield or brownfield. See the install guide for current steps.
The six AID phases (plus the optional Deploy and Monitor skills) are the glue that connects these tools into a coherent pipeline. Each phase can work standalone or as part of the full lifecycle.
It's Waterfall. And That's the Point.
Let's say the quiet part out loud.
Understand → Specify → Plan → Build → Verify → Ship. That's Waterfall.
Waterfall failed because humans were too slow to execute its phases, too expensive to iterate, and too inconsistent to maintain documents. Agile was the correct response to Waterfall's execution problem.
But Agile threw out something valuable: rigor. Understanding before building. Specifying before coding. Verifying against a spec, not just "does it feel right."
AI changes the economics:
- Discovery that took weeks takes hours
- Specs that took days take minutes
- Going back costs tokens, not sprints
- Documents are maintained by the same agents that write code — they don't rot
Agile was the right answer to Waterfall's execution problem. AI is the right answer to Agile's rigor problem.
AID is Waterfall with AI execution and formal feedback loops — the methodology that finally works because the bottleneck moved from "humans are slow" to "humans set direction."
The Full Pipeline
Six numbered phases, plus two optional Deliver skills. Eleven feedback loops. The Knowledge Base is the center.
The six numbered phases run in sequence, each ending at a human gate:
- 1. Discover — Map the existing codebase into the Knowledge Base.
- 2. Interview — Gather requirements conversationally.
- 3. Specify — Turn features into technical specs.
- 4. Plan — Sequence specs into deliveries.
- 5. Detail — Break deliveries into typed, ordered tasks.
- 6. Execute — Run tasks with a built-in adversarial review gate.
- Optional: Deploy + Monitor — Ship, observe production, classify, and route what breaks back into the pipeline.
Each phase is an independent, composable skill. Use Discovery alone on a brownfield codebase. Use Execute's review as a standalone quality gate. Use Monitor to observe production without adopting the full pipeline. The value compounds when combined, but each phase stands on its own.
Problem 6: Memory Without a Map Is Just Storage
The Knowledge Base solves the what to remember problem. It doesn't solve the how to find it problem.
A common failure mode: an agent receives a task spec and implements something technically correct — then review catches that it violated a naming convention documented in coding-standards.md. The agent didn't ignore the convention. It didn't know the document existed. The fix goes through review, gets rejected, comes back, costs twice as much.
The bottleneck isn't retrieval speed — the KB is small enough (14 documents, typically 2-20KB each) that any agent can read any document in milliseconds. The bottleneck is knowing what exists.
AID's answer: the Context Index.
The Discovery phase generates .aid/knowledge/INDEX.md as its final step — a lightweight summary of every KB document, 2-3 lines each. It costs ~200-500 tokens to include in an agent's context. It gives the agent the ability to self-serve.
.aid/knowledge/INDEX.md
| Document | Summary |
|---------------------|------------------------------------------------------------|
| architecture.md | MVVM + Clean Architecture. Service registration in |
| | ServiceCollectionExtensions.cs. Navigation via |
| | INavigationService. |
| coding-standards.md | PascalCase for public, _camelCase for fields. Result<T> |
| | for error handling. Async suffix on all async methods. |
| data-model.md | SQLite via EF Core. 8 entities. Soft deletes on Recording |
| | and Transcript. |The protocol is simple:
- Every task receives INDEX.md. Always. It's the map.
- The orchestrator selects 2-4 relevant KB docs based on the task's domain.
- The task includes a search instruction: "If you need context not provided, consult
INDEX.mdand read the relevant document before making assumptions." - Review validates context usage. Did the agent use available KB context, or did it guess?
This is RAG by convention — not embeddings and vector databases, but predictable file structure and an index that agents can navigate. The agent has filesystem access. It can read on demand. It just needs the menu.
Why not a vector database? Because convention beats infrastructure when the corpus is small. The agent can read any KB document in milliseconds. The problem was never retrieval — it was discovery.
What AID Is Not
Not anti-SDD. SDD got the core insight right: specs should be first-class artifacts and AI should execute from specs. AID agrees and builds on top.
Not anti-Agile. Agile's emphasis on iteration and working software remains valuable. AID's feedback loops are inspired by Agile's adaptability.
Not theoretical. Everything described here runs in production today. A desktop app with 1,184 tests across unit and E2E. An enterprise Java analysis on a 21GB codebase. A data pipeline serving three e-commerce brands with automated quality gates.
AID is SDD completed. The missing stages (discovery, interview, testing, post-production monitoring). The missing feedback (formal loops from production back to development). The missing scope (the full pipeline — two-level planning, staging validation, operations, quality gates, bug triage, and the full production lifecycle). The missing vocabulary (Knowledge Base, impediments, domain validation, triage). The missing framing (human-in-the-middle, not human-on-the-side).
What's Next
AID is a methodology, not a product. Each phase can be implemented as an agent skill, a prompt template, a CI workflow — whatever fits your stack. Claude Code, Codex, Cursor, Windsurf, Aider — the tooling doesn't matter. The discipline does.
The reference implementation is open-source — skill definitions, agent configurations, and document templates for each phase: github.com/AndreVianna/aid-methodology. Install the persistent aid CLI, run aid add <tool> in your repo, then /aid-config to scaffold the Knowledge Base. Read the full documentation at aid.casuloailabs.com and the install guide to get started.
SDD says: specs drive the code.
AID says: understanding drives the specs. AI amplifies the human. The human drives the AI.
Andre Vianna is a software architect with 30+ years of experience. Lola Lovelace is his AI partner and co-architect at Casulo AI Labs. The AID methodology was developed through their daily production collaboration across greenfield, brownfield, and operational projects.
Updated 2026-06-08. When this post was first written, the aid-init bootstrapping step, the 15-document Knowledge Base, and the "four stages / nine phases / ten feedback loops" model were all accurate. AID has since evolved: installation is a persistent aid CLI (no aid-init), the Knowledge Base is 14 standard documents plus three meta-docs, and the pipeline is six numbered phases (Discover → Execute) with two optional Deliver skills (Deploy, Monitor) and eleven feedback loops. The text above has been corrected; see the live documentation for the current details.